Introduction to Baremetal
Once you've grown beyond the confines and limitations of the cloud deployment providers, it's time to get serious: hosting your own code on big iron. Prepare for performance like you've only dreamed of! Also be prepared for IT and infrastructure responsibilities like you've only had nightmares of.
With Redwood's Baremetal deployment option, the source (like your dev machine) will SSH into one or more remote machines and execute commands in order to update your codebase, run any database migrations and restart services.
Deploying from a client (like your own development machine) consists of running a single command:
First time deploy:
yarn rw deploy baremetal production --first-run
Subsequent deploys:
yarn rw deploy baremetal production
Deployment Lifecycle
The Baremetal deploy runs several commands in sequence. These can be customized, to an extent, and some of them skipped completely:
git clone --depth=1to retrieve the latest code- Symlink the latest deploy
.envto the shared.envin the app dir yarn install- installs dependencies- Runs prisma DB migrations
- Generate Prisma client libs
- Runs data migrations
- Builds the web and/or api sides
- Symlink the latest deploy dir to
currentin the app dir - Restart the serving process(es)
- Remove older deploy directories
First Run Lifecycle
If the --first-run flag is specified then step 6 above will execute the following commands instead:
pm2 start [service]- starts the serving process(es)pm2 save- saves the running services to the deploy users config file for future startup. See Starting on Reboot for further information
Directory Structure
Once you're deployed and running, you'll find a directory structure that looks like this:
└── var
└── www
└── myapp
├── .env <────────────────┐
├── current ───symlink──┐ │
└── releases │ │
└── 20220420120000 <┘ │
├── .env ─symlink─┘
├── api
├── web
├── ...
There's a symlink current pointing to directory named for a timestamp (the timestamp of the last deploy) and within that is your codebase, the latest revision having been cloned. The .env file in that directory is then symlinked back out to the one in the root of your app path, so that it can be shared across deployments.
So a reference to /var/www/myapp/current will always be the latest deployed version of your codebase. If you wanted to setup nginx to serve your web side, you would point it to /var/www/myapp/current/web/dist as the root and it will always be serving the latest code: a new deploy will change the current symlink and nginx will start serving the new files instantaneously.
App Setup
Run the following to add the required config files to your codebase:
yarn rw setup deploy baremetal
This will add dependencies to your package.json and create two files:
deploy.tomlcontains server config for knowing which machines to connect to and which commands to runecosystem.config.jsfor PM2 to know what service(s) to monitor
If you see an error from gyp you may need to add some additional dependencies before yarn install will be able to complete. See the README for node-type for more info: https://github.com/nodejs/node-gyp#installation
Configuration
Before your first deploy you'll need to add some configuration.
ecosystem.config.js
By default, baremetal assumes you want to run the yarn rw serve command, which provides both the web and api sides. The web side will be available on port 8910 unless you update your redwood.toml file to make it available on another port. The default generated ecosystem.config.js will contain this config only, within a service called "serve":
module.exports = {
apps: [
{
name: 'serve',
cwd: 'current',
script: 'node_modules/.bin/rw',
args: 'serve',
instances: 'max',
exec_mode: 'cluster',
wait_ready: true,
listen_timeout: 10000,
},
],
}
If you follow our recommended config below, you could update this to only serve the api side, because the web side will be handled by nginx. That could look like:
module.exports = {
apps: [
{
name: 'api',
cwd: 'current',
script: 'node_modules/.bin/rw',
args: 'serve api',
instances: 'max',
exec_mode: 'cluster',
wait_ready: true,
listen_timeout: 10000,
},
],
}
deploy.toml
This file contains your server configuration: which servers to connect to and which commands to run on them.
[[production.servers]]
host = "server.com"
username = "user"
agentForward = true
sides = ["api","web"]
packageManagerCommand = "yarn"
monitorCommand = "pm2"
path = "/var/www/app"
processNames = ["serve"]
repo = "git@github.com:myorg/myapp.git"
branch = "main"
keepReleases = 5
This lists a single server, in the production environment, providing the hostname and connection details (username and agentForward), which sides are hosted on this server (by default it's both web and api sides), the path to the app code and then which PM2 service names should be (re)started on this server.
Config Options
host- hostname to the serverusername- the user to login aspassword- [optional] if you are using password authentication, include that hereprivateKey- [optional] if you connect with a private key, include the path to the key herepassphrase- [optional] if your private key contains a passphrase, enter it hereagentForward- [optional] if you have agent forwarding enabled, set this totrueand your own credentials will be used for further SSH connections from the server (like when connecting to GitHub)sides- An array of sides that will be built on this serverpackageManagerCommand- The package manager bin to call, defaults toyarnbut could be updated to be prefixed with another command first, for example:doppler run -- yarnmonitorCommand- The monitor bin to call, defaults topm2but could be updated to be prefixed with another command first, for example:doppler run -- pm2path- The absolute path to the root of the application on the servermigrate- [optional] Whether or not to run migration processes on this server, defaults totrueprocessNames- An array of service names fromecosystem.config.jswhich will be (re)started on a successful deployrepo- The path to the git repo to clonebranch- [optional] The branch to deploy (defaults tomain)keepReleases- [optional] The number of previous releases to keep on the server, including the one currently being served (defaults to 5)
The easiest connection method is generally to include your own public key in the server's ~/.ssh/authorized_keys file, enable agent forwarding, and then set agentForward = true in deploy.toml. This will allow you to use your own credentials when pulling code from GitHub (required for private repos). Otherwise you can create a deploy key and keep it on the server.
Multiple Servers
If you start horizontally scaling your application you may find it necessary to have the web and api sides served from different servers. The configuration files can accommodate this:
[[production.servers]]
host = "api.server.com"
username = "user"
agentForward = true
sides = ["api"]
path = "/var/www/app"
processNames = ["api"]
[[production.servers]]
host = "web.server.com"
username = "user"
agentForward = true
sides = ["web"]
path = "/var/www/app"
migrate = false
processNames = ["web"]
module.exports = {
apps: [
{
name: 'api',
cwd: 'current',
script: 'node_modules/.bin/rw',
args: 'serve api',
instances: 'max',
exec_mode: 'cluster',
wait_ready: true,
listen_timeout: 10000,
},
{
name: 'web',
cwd: 'current',
script: 'node_modules/.bin/rw',
args: 'serve web',
instances: 'max',
exec_mode: 'cluster',
wait_ready: true,
listen_timeout: 10000,
},
],
}
Note the inclusion of migrate = false so that migrations are not run again on the web server (they only need to run once and it makes sense to keep them with the api side).
You can add as many [[servers]] blocks as you need.
Multiple Environments
You can deploy to multiple environments from a single deploy.toml by including servers grouped by environment name:
[[production.servers]]
host = "prod.server.com"
username = "user"
agentForward = true
sides = ["api", "web"]
path = "/var/www/app"
processNames = ["serve"]
[[staging.servers]]
host = "staging.server.com"
username = "user"
agentForward = true
sides = ["api", "web"]
path = "/var/www/app"
processNames = ["serve", "stage-logging"]
At deploy time, include the environment in the command:
yarn rw deploy baremetal staging
Note that the codebase shares a single ecosystem.config.js file. If you need a different set of services running in different environments you'll need to simply give them a unique name and reference them in the processNames option of deploy.toml (see the additional stage-logging process in the above example).
Server Setup
You will need to create the directory in which your app code will live. This path will be the path var in deploy.toml. Make sure the username you will connect as in deploy.toml has permission to read/write/execute files in this directory. For example, if your /var dir is owned by root, but you're going to deploy with a user named deploy:
sudo mkdir -p /var/www/myapp
sudo chown deploy:deploy /var/www/myapp
You'll want to create an .env file in this directory containing any environment variables that are needed by your by your app (like DATABASE_URL at a minimum). This will be symlinked to each release directory so that it's available as the app expects (in the root directory of the codebase).
The deployment process uses a 'non-interactive' SSH session to run commands on the remote server. A non-interactive session will often load a minimal amount of settings for better compatibility and speed. In some versions of Linux .bashrc by default does not load (by design) from a non-interactive session. This can lead to yarn (or other commands) not being found by the deployment script, even though they are in your path, because additional ENV vars are set in ~/.bashrc which provide things like NPM paths and setup.
A quick fix on some distros is to edit the deployment user's ~/.bashrc file and comment out the lines that stop non-interactive processing.
# If not running interactively, don't do anything
- case $- in
- *i*) ;;
- *) return;;
- esac
# If not running interactively, don't do anything
+ # case $- in
+ # *i*) ;;
+ # *) return;;
+ # esac
This may also be a one-liner like:
- [ -z "$PS1" ] && return
+ # [ -z "$PS1" ] && return
There are techniques for getting node, npm and yarn to be available without loading everything in .bashrc. See this comment for some ideas.
First Deploy
Back on your development machine, enter your details in deploy.toml, commit it and push it up, and then try a first deploy:
yarn rw deploy baremetal production --first-run
If there are any issues the deploy should stop and you'll see the error message printed to the console.
If it worked, hooray! You're deployed to BAREMETAL. If not, read on...
Troubleshooting
On the server you should see a new directory inside the path you defined in deploy.toml. It should be a timestamp of the deploy, like:
drwxrwxr-x 7 ubuntu ubuntu 4096 Apr 22 23:00 ./
drwxr-xr-x 7 ubuntu ubuntu 4096 Apr 22 22:46 ../
-rw-rw-r-- 1 ubuntu ubuntu 1167 Apr 22 20:49 .env
drwxrwxr-x 10 ubuntu ubuntu 4096 Apr 22 21:43 20220422214218/
You may or may not also have a current symlink in the app directory pointing to that timestamp directory (it depends how far the deploy script got before it failed as to whether you'll have the symlink or not).
cd into that timestamped directory and check that you have a .env symlink pointing back to the app directory's .env file.
Next, try performing all of the steps yourself that would happen during a deploy:
yarn install
yarn rw prisma migrate deploy
yarn rw prisma generate
yarn rw dataMigrate up
yarn rw build
ln -nsf "$(pwd)" ../current
If they worked for you, the deploy process should have no problem as it runs the same commands (after all, it connects via SSH and runs the same commands you just did!)
Next we can check that the site is being served correctly. Run yarn rw serve and make sure your processes start and are accessible (by default on port 8910):
curl http://localhost:8910
# or
wget http://localhost:8910
If you don't see the content of your web/src/index.html file then something isn't working. You'll need to fix those issues before you can deploy. Verify the api side is responding:
curl http://localhost:8910/.redwood/functions/graphql?query={redwood{version}}
# or
wget http://localhost:8910/.redwood/functions/graphql?query={redwood{version}}
You should see something like:
{
"data": {
"redwood": {
"version": "1.0.0"
}
}
}
If so then your API side is up and running! The only thing left to test is that the api side has access to the database. This call would be pretty specific to your app, but assuming you have port 8910 open to the world you could simply open a browser to click around to find a page that makes a database request.
Was the problem with starting your PM2 process? That will be harder to debug here in this doc, but visit us in the forums or Discord and we'll try to help!
Starting Processes on Server Restart
The pm2 service requires some system "hooks" to be installed so it can boot up using your system's service manager. Otherwise, your PM2 services will need to be manually started again on a server restart. These steps only need to be run the first time you install PM2.
SSH into your server and then run:
pm2 startup
You will see some output similar to the output below. We care about the output after "copy/paste the following command:" You'll need to do just that: copy the command starting with sudo and then paste and execute it. Note this command uses sudo so you'll need the root password to the machine in order for it to complete successfully.
The below text is example output, yours will be different, don't copy and paste ours!
$ pm2 startup
[PM2] Init System found: systemd
[PM2] To setup the Startup Script, copy/paste the following command:
// highlight-next-line
sudo env PATH=$PATH:/home/ubuntu/.nvm/versions/node/v16.13.2/bin /home/ubuntu/.nvm/versions/node/v16.13.2/lib/node_modules/pm2/bin/pm2 startup systemd -u ubuntu --hp /home/ubuntu
In this example, you would copy sudo env PATH=$PATH:/home/ubuntu/.nvm/versions/node/v16.13.2/bin /home/ubuntu/.nvm/versions/node/v16.13.2/lib/node_modules/pm2/bin/pm2 startup systemd -u ubuntu --hp /home/ubuntu and run it. You should get a bunch of output along with [PM2] [v] Command successfully executed. near the end. Now if your server restarts for whatever reason, your PM2 processes will be restarted once the server is back up.
Customizing the Deploy
There are several ways you can customize the deploys steps, whether that's skipping steps completely, or inserting your own commands before or after the default ones.
Skipping Steps
If you want to speed things up you can skip one or more steps during the deploy. For example, if you have no database migrations, you can skip them completely and save some time:
yarn rw deploy baremetal production --no-migrate
Run yarn rw deploy baremetal --help for the full list of flags. You can set them as --migrate=false or use the --no-migrate variant.
Inserting Custom Commands
Baremetal supports running your own custom commands before or after the regular deploy commands. You can run commands before and/or after the built-in commands. Your custom commands are defined in the deploy.toml config file. The existing commands that you can hook into are:
update- cloning the codebasesymlinkEnv- symlink the new deploy's.envto shared one in the app dirinstall-yarn installmigrate- database migrationsbuild-yarn build(your custom before/after command is run for each side being built)symlinkCurrent- symlink the new deploy dir tocurrentin the app dirrestart- (re)starting any pm2 processes (your custom command will run before/after each process is restarted)cleanup- cleaning up any old releases
You can define your before/after commands in three different places:
- Globally - runs for any environment
- Environment specific - runs for only a single environment
- Server specific - runs for only a single server in a single environment
Custom commands are run in the new deploy directory, not the root of your application directory. During a deploy the current symlink will point to the previous directory while your code is executed in the new one, before the current symlink location is updated.
drwxrwxr-x 5 ubuntu ubuntu 4096 May 10 18:20 ./
drwxr-xr-x 7 ubuntu ubuntu 4096 Apr 27 17:43 ../
drwxrwxr-x 2 ubuntu ubuntu 4096 May 9 22:59 20220503211428/
drwxrwxr-x 2 ubuntu ubuntu 4096 May 9 22:59 20220503211429/
drwxrwxr-x 10 ubuntu ubuntu 4096 May 10 18:18 20220510181730/ <-- commands are run in here
lrwxrwxrwx 1 ubuntu ubuntu 14 May 10 18:19 current -> 20220503211429/
-rw-rw-r-- 1 ubuntu ubuntu 1167 Apr 22 20:49 .env
Syntax
Global events are defined in a [before] and/or [after] block in your deploy.toml file:
[before]
install = "touch install.lock"
[after]
install = "rm install.lock"
[[production.servers]]
host = 'server.com'
# ...
Environment specific commands are defined in a [[environment.before]] and [[environment.after]] block:
[production.before]
install = "touch prod-install.lock"
[production.after]
install = "rm prod-install.lock"
[production.servers]
host = 'server.com'
# ...
Server specific commands are defined with a before.command and after.command key directly in your server config:
[[production.servers]]
host = 'server.com'
# ...
before.install = 'touch server-install.lock'
after.install = 'rm server-install.lock'
You can define commands as a string, or an array of strings if you want to run multiple commands:
[before]
install = ["echo 'started at $(date)' > install.lock", "cp -R . ../backup"]
[[production.servers]]
host = 'server.com'
# ...
You can include commands in any/all of the three configurations (global, env and server) and they will all be stacked up and run in that order: global -> environment -> server. For example:
[[production.servers]]
host = 'server.com'
# ...
before.install = 'touch server-install.lock'
[production.before]
install = ['touch prod-install1.lock', 'touch prod-install2.lock']
[before]
install = 'touch install.lock'
Would result in the commands running in this order, all before running yarn install:
touch install.locktouch prod-install1.locktouch prod-install2.locktouch server-install.lock
Rollback
If you deploy and find something has gone horribly wrong, you can rollback your deploy to the previous release:
yarn rw deploy baremetal production --rollback
You can even rollback multiple deploys, up to the total number you still have denoted with the keepReleases option:
yarn rw deploy baremetal production --rollback 3
Note that this will not rollback your database—if you had a release that changed the database, that updated database will still be in effect, but with the previous version of the web and api sides. Trying to undo database migrations is a very difficult proposition and isn't even possible in many cases.
Make sure to thoroughly test releases that change the database before doing it for real!
Maintenance Page
If you find that you have a particular complex deploy, one that may involve incompatible database changes with the current codebase, or want to make sure that database changes don't occur while in the middle of a deploy, you can put up a maintenance page:
yarn rw deploy baremetal production --maintenance up
It does this by replacing web/dist/200.html with web/src/maintenance.html. This means any new web requests, at any URL, will show the maintenance page. This process also stops any services listed in the processNames option of deploy.toml—this is important for the api server as it will otherwise keep serving requests to users currently running the app, even though no new users can get the Javascript packages required to start a new session in their browser.
You can remove the maintenance page with:
yarn rw deploy baremetal production --maintenance down
Note that the maintenance page will automatically come down as the result of a new deploy as it checks out a new copy of the codebase (with a brand new copy of web/dist/200.html and will automatically restart services (bring them all back online).
Monitoring
PM2 has a nice terminal-based dashboard for monitoring your services:
pm2 monit
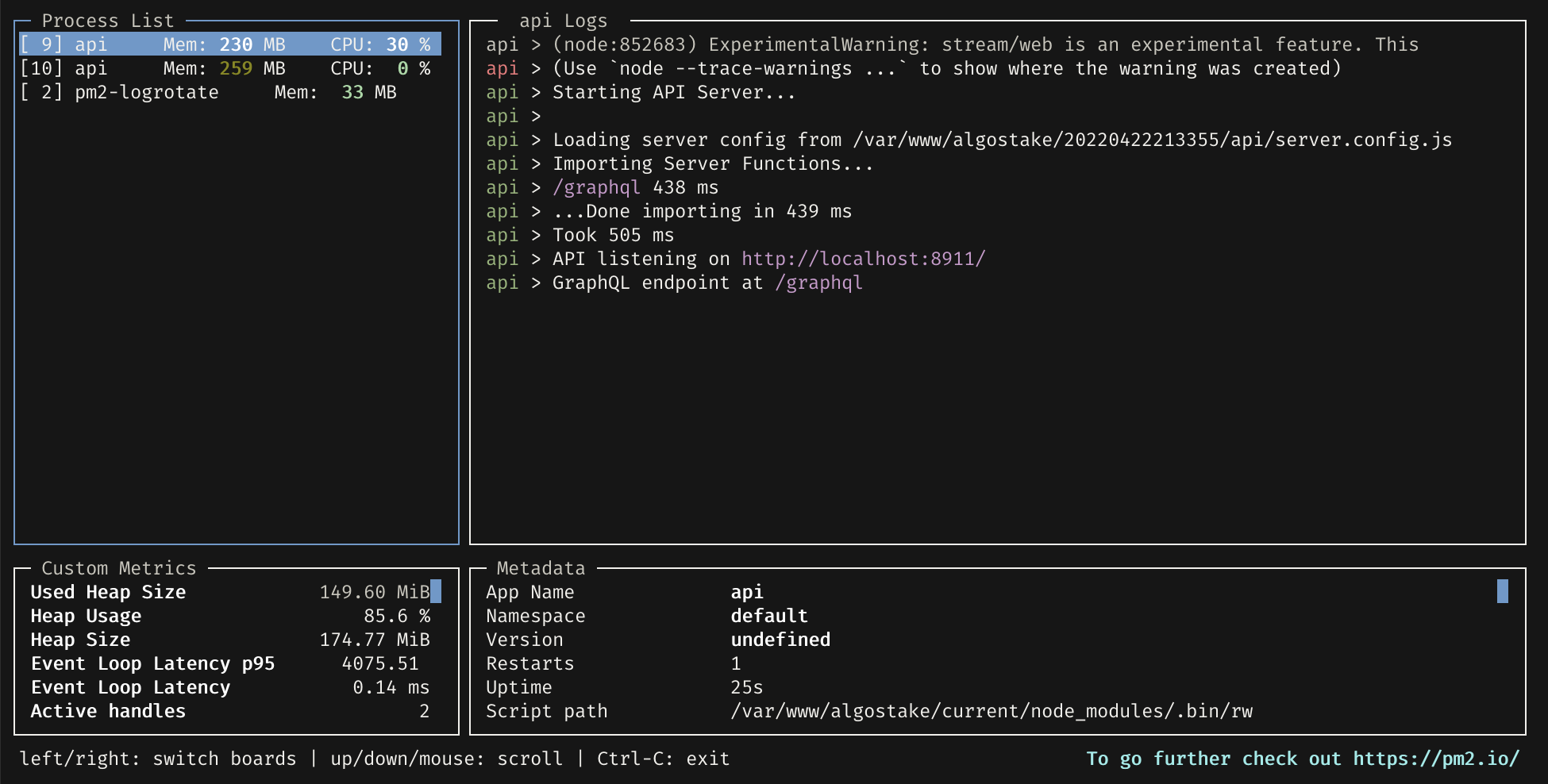
And even a web-based UI with paid upgrades if you need to give normies access to your monitoring data:
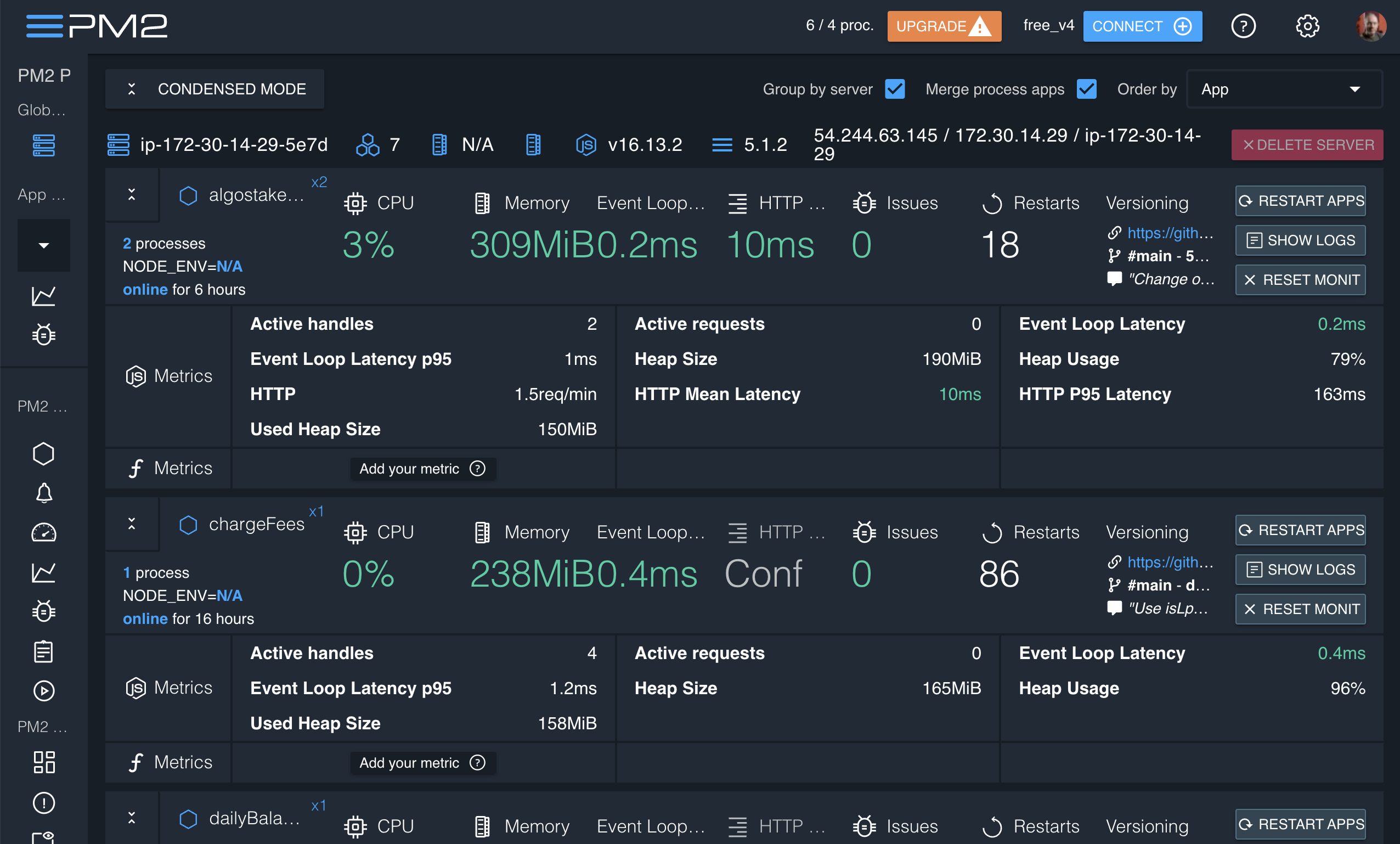
Example Server Configurations
The default configuration, which requires the least amount of manual configuration, is to serve both the web and api sides, with the web side being bound to port 8910. This isn't really feasible for a general web app which should be available on port 80 (for HTTP) and/or port 443 (for HTTPS). Here are some custom configs to help.
Redwood Serves Web and Api Sides, Bind to Port 80
This is almost as easy as the default configuration, you just need to tell Redwood to bind to port 80. However, most *nix distributions will not allow a process to bind to ports lower than 1024 without root/sudo permissions. There is a command you can run to allow access to a specific binary (node in this case) to bind to one of those ports anyway.
Tell Redwood to Bind to Port 80
Update the [web] port:
[web]
title = "My Application"
apiUrl = "/.netlify/functions"
+ port = 80
[api]
port = 8911
[browser]
open = true
Allow Node to Bind to Port 80
Use the setcap utility to provide access to lower ports by a given process:
sudo setcap CAP_NET_BIND_SERVICE=+eip $(which node)
Now restart your service and it should be available on port 80:
pm2 restart serve
This should get your site available on port 80 (for HTTP), but you really want it available on port 443 (for HTTPS). That won't be easy if you continue to use Redwood's internal web server. See the next recipe for a solution.
Redwood Serves Api, Nginx Serves Web Side
Coming soon!